Information processing and cross-linguistic universals
One goal of work in our lab is to try to explain the evolution of language in terms of information theory and information processing. This is a very different approach than that taken by Chomsky, who has famously argued that language is not evolved for ease of processing or communication. The approach in my lab is to take the information processing approach as far as we can. It turns out to be a productive research plan.
There are several authors on this work, including many recent students in the lab:
Steve Piantadosi, Leon Bergen, Kyle Mahowald, Richard Futrell, Melissa Kline
The summary below is divided into 2 parts: (1) words: the evolution of dictionaries; (2) sentence structure (syntax).
Words
Language for communication
Summary of some key ideas in Piantadosi, Tily & Gibson (2012):
One obvious hypothesis is that human languages have evolved for communicative purposes. This idea is more controversial than you might think. Here is a recent quote from the world’s most famous linguist, Noam Chomsky:
“The natural approach has always been: Is it well designed for use, understood typically as use for communication? I think that’s the wrong question. The use of language for communication might turn out to be a kind of epiphenomenon. … If you want to make sure that we never misunderstand one another, for that purpose language is not well designed, because you have such properties as ambiguity. If we want to have the property that the things that we usually would like to say come out short and simple, well, it probably doesn’t have that property.” (Chomsky, 2002, p. 107)
This quote is from 2002, but if you talk to Chomsky today, he will say pretty much the same thing.
Chomsky is right that human language is very ambiguous. For example, words are very ambiguous. Take the word “take” for example. It has over 20 senses in any dictionary. Or take the word “to” in normal speech. That can be a preposition, or numeral, or a synonym for “also”. Syntax is also very ambiguous. Take the sentence “The man saw the woman with the telescope”. Does the man have the telescope? Or is it the woman? The sentence is completely ambiguous between these two readings. And if you look at a random 30 word sentence from today’s newspaper, it will have hundreds or even thousands of possible interpretations. One of the big problems facing natural language processing systems (so-called artificial intelligence or AI systems) is resolving this ambiguity.
So to summarize Chomsky’s view, he thinks that language couldn’t be evolved for communication because human language is very ambiguous, and ambiguity is obviously not beneficial for communication. But there is a major flaw in this reasoning: while it’s true that human language is very ambiguous out of context, human language is actually rarely ambiguous in context. That is, context almost always resolves this ambiguity.
So for example, consider the word “to”. This word is very ambiguous, with at least 4 senses in spoken language. But it is almost always disambiguated by the context, as we see in these examples: John wanted to run., John went to school., John wanted two dollars., Sam wanted some money too. In these cases, the syntactic context disambiguates. The same general thing happens for all other kinds of ambiguity: the preceding context disambiguates what was intended. So when you read the newspaper, you aren’t confused by the hundreds of possible interpretations of the syntax of a long sentence: you usually understand the one that is intended. So while ambiguity is a real problem for AI systems, it’s not a problem for humans. AI systems are trying to do what humans can do in disambiguating language in context.
This is called the information theoretic or communication-theory approach to language structure, due originally to Claude Shannon in the 1940s. Chomsky derailed it a bit for 50 years, but the communication theory approach is now becoming important again as a way to understand human language.
Because context generally disambiguates, we can re-use elements that are short, and hence good for communication (keeping the code short, following Shannon’s information theory), as long as the context disambiguates these. We see this in lexical ambiguity: languages generally are more ambiguous for shorter words. We show this rigorously for three languages for which we had complete dictionaries of word senses: English, German and Dutch. For each of these languages, 1 syllable words are more ambiguous than 2 syllable words; 2 syllable words are more ambiguous than 3 syllable words; etc. For all possible comparisons, this turns out to be true.
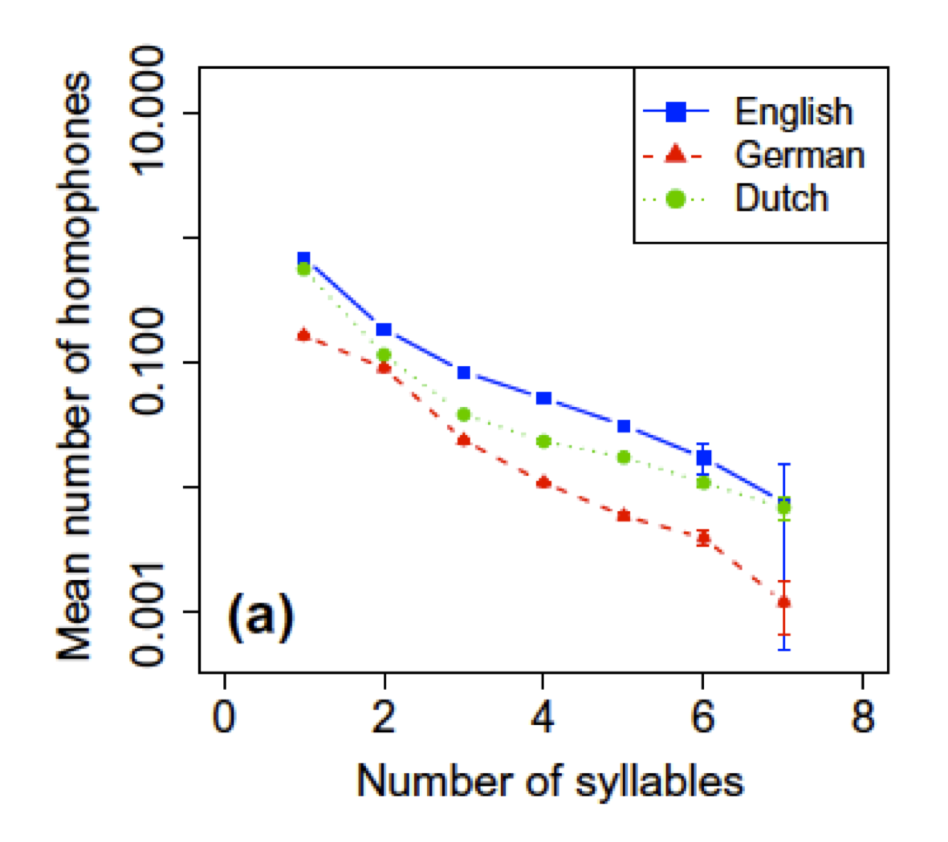
Thus, the information theoretic approach to lexicons appears to be on the right track. Furthermore, Chomsky’s idea of what language was evolved for — complex thought — doesn’t make any of these predictions. So our results are just a surprise to his alternative.
Word lengths are predicted by their information content.
Summary of some key ideas in Piantadosi, Tily & Gibson (2011):
According to the information theory approach, a shorter code is a better code, because we don’t have to say so much. One interesting prediction of the information theoretic approach to language structure is that more frequent words should be shorter than less frequent ones. So the most frequent words (like “the”, “of”, “a” and “boy”) are shorter than the less frequent words (like “refrigerator” and “orangutan”). In fact this was shown by a famous Harvard linguist called George Kingsley Zipf in the 1940s: this is one of what are known as Zipf’s Laws: more frequent words are shorter.
Recently, my group was able to test a stronger prediction of the information theoretic approach to word structures. The prediction is that word length should depend not only on word frequency out of context, but also on the predictability of the word in the preceding context. That is, the more predictable the word is, given the preceding context, the shorter the word should be. We tested this by looking at a very simplistic notion of context: the preceding 2 words. Then we looked at huge texts for 11 languages (all that we could get our hands on at the time). We wanted to know whether words were shorter if they were more predictable following the preceding two words. And it turns out that this is robustly true in all languages that we looked at then, and all the languages that we have looked at since.
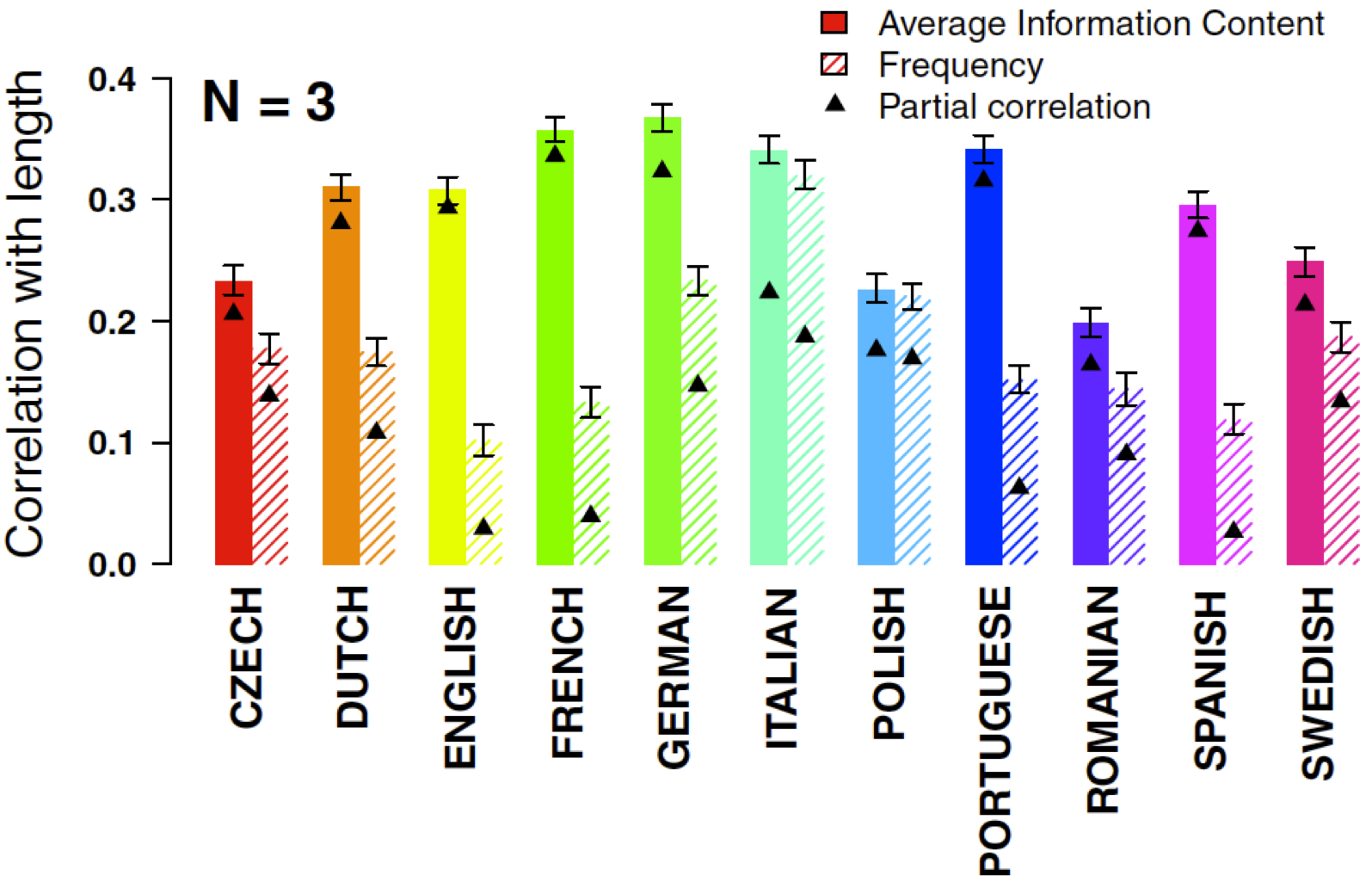
In the figure, we have results from 11 languages. There are two bars for each language: the size of the correlation between word length and word frequency (the striped bars: this is the Zipf rule), and the size of the correlation between word length and word predictability given the preceding two words (the solid bars). You can see by looking at the graphs that the solid bars are larger than the striped bars in all languages. This shows that predictability in context is a better predictor of word length across the world’s lexicons than simple word frequency. This is support for the information theoretic approach to language structure, in the structure of lexicons.
In followup work led by Kyle Mahowald, we showed that shorter versions of synonymous word pairs like math / mathematics or exam/examination appear in more predictable environments, and that people rate the shorter version as better in a more predictable context, but less so for the longer words. Overall, these results suggest that information-theoretic conditions are a part of a speaker’s knowledge and play a causal role in language change.
Language as efficient communication in the domain of color words.
It has long been known that cultures vary widely in the set of color words that they typically use, from as few as 2 or 3 words typically used (e.g., the Dani of Papua New Guinea, as reported in Heider, 1972), to as many as 11-12 (e.g., English, Spanish, Russian). There are two typical explanations in the literature for such variability: (1) the universalist hypothesis, whereby the visual system drives our way of partitioning the color space (Berlin & Kay, 1969; Regier et al., 2007); and (2) the linguistic-relativity hypothesis, whereby the language that we speak somehow causes biases in the color space partitioning. In recent work, we have been pursuing a third hypothesis — the efficient-communication hypothesis (Regier, Kemp & Kay, 2014) — which postulates that all people with genetically normal vision have similar color perception, but vary in their color language depending on the usefulness of color to behavior. We have evaluated this in a remote tribe in the Bolivian Amazonian region: the Tsimane’. Our results include the following (cf. Lindsey et al. 2015, for similar results to some of these questions):
- The Tsimane’ are idiosyncratic in the color terms used to label color chips or naturally colored objects.
- The Tsimane’ are less likely than English speakers to use color terms spontaneously in a contrastive object-labeling task.
- The Tsimane’ take longer than English speakers to label chip colors, but not objects.
- Tsimane’ is not an unusual language / culture in the WCS: typical uncertainty; typical number of “basic” color terms.
Together, these results suggest that the variability in the number of color terms across cultures is not due to language itself, nor due to an innate set of universal color categories, but rather due to variability in the relative cost-benefit associated with expanding color vocabulary.
(The paper described here is currently under review. When it is accepted for publication, I will update this section to include the relevant figures.)
Sentence structure: Syntax
Language for communication: The rational integration of noise and prior lexical, syntactic and semantic expectation in language interpretation
We start with sentence interpretation (not structure), with the idea that understanding how language is processed may lead us to an understanding of how language is shaped in evolution.
People’s interpretations of sentences can be explained in terms of Shannon’s noisy channel idea, where the listener is trying to guess what the speaker said, given a noisy channel. Gibson et al. (2013) works out this idea, and provides simple experimental in support of the claims.
My favorite noisy-channel example is from an Australian newspaper “The Bulletin” from a few years ago:

Thinking about language comprehension through a noisy channel, as a listener / reader, I am trying to guess what sentence was said, given what I heard / read. That is, I am attempting to maximize the probability of S_intended given S_perceived. We can break that contingency into a prior term (P (S_intended)) and a likelihood term (the noise term): how likely it is that S_intended became S_perceived: Maximize P(s_i | s_p) by maximizing P(s_i) * P(s_i → s_p)
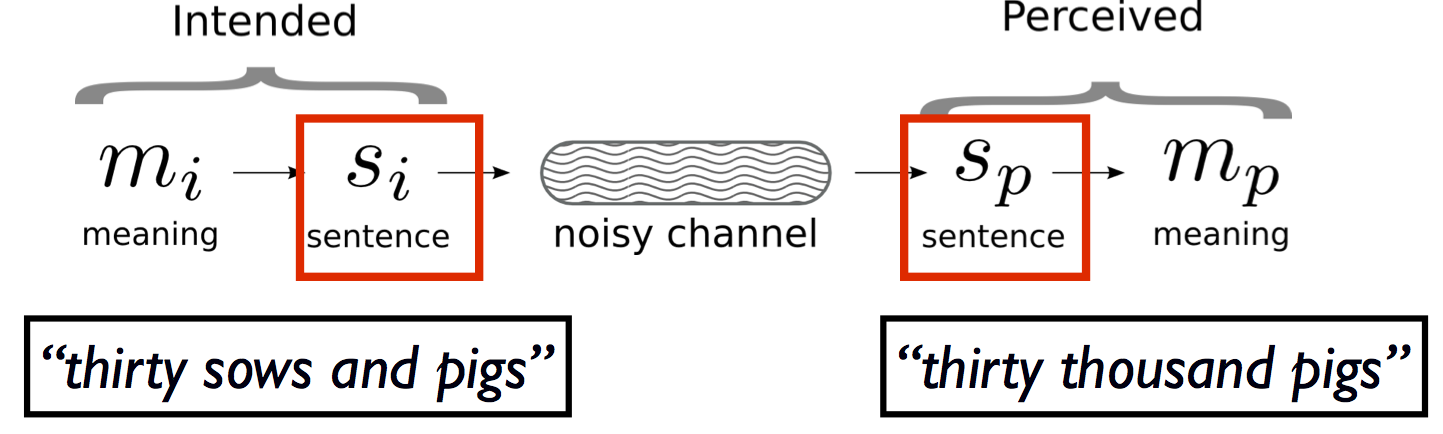
So even though the farmer may have said “thirty sows and pigs”, it was heard by the reporter as “thirty thousand pigs”, for two reasons (1) the language prior: the sequence “thirty thousand” is much more expected in the language model than the sequence “thirty sows and…” (the word “sow” is very infrequent in non-farmer dialects); and (2) this error model is such that “sows and” is very close to “thousand” in terms of their production and comprehension (it is hard to tell the difference between the sounds “th” and “s”). (Note that this mis-hearing took place in spite of the fact that the world-knowledge prior makes this interpretation very unlikely: it’s a very weird world situation to have 30,000 pigs in the river. This just means that the language prior was very strong for the journalist in question, such that s/he didn’t even notice that what they were quoting was unlikely to be true.)
In the paper, we show that people’s interpretations of sentences depend on:
- The proximity of a plausible alternative, where fewer edits to get to an alternative means that the alternative will more likely be considered.
- Noise in the environment.
- Prior expectations about what people are likely to say.
1. The proximity of a plausible alternative, where fewer edits to get to an alternative means that the alternative will more likely be considered.
To do this, we considered 5 English syntactic alternations, where a syntactic alternation is just two different syntactic ways to say the same thing. All languages have syntactic alternations because, when we talk, we want to start with old information (what we are currently thinking and talking about), and progress to new information. For example, suppose that I want to tell you that Mary was hired by Microsoft. If we are talking about Mary, I might say “Hey, did you know that Mary was hired by Microsoft?” (a passive construction, starting with “Mary”). But if we were talking about Microsoft (or companies like that, more generally) then I might say “Hey, did you know that Microsoft hired Mary?” (an active construction). This is the active-passive alternation. Another alternation that we consider in the paper is the double-object / preposition-phrase object (DO/PO) construction, whereby I might say “I gave Mary the book” (DO) or “I gave the book to Mary” (PO).
In the task in the paper, we presented people with implausible materials that could be edited by inserting or deleting some function words in order to get to a much more plausible alternative. For example, consider a-d:
a. The ball kicked the girl. (Two deletions away from the passive “The ball was kicked by girl”)
b. The girl was kicked by the ball. (Two insertions away from the active “The girl kicked the ball”)
c. I gave a book Mary. (One deletion away from the PO “I gave a book to Mary”)
d. I gave Mary to a book. (One insertion away from the DO “I gave Mary a book”)
Each of 5 experiments looked at a single alternation each (i.e., active/passive in one experiment, DO/PO in another, etc.) We presented 5 implausible examples of each version of the alternation, intermixed with 70 distractor materials, which were plausible, and we asked a comprehension question after each item. The comprehension question allowed us to determine which interpretation a participant obtained. (We only analyzed participants’ data if they got most of the questions following plausible items correct.) For example, after (a), we might ask “Did the girl kick someone / something?”. Here the answer “no” means that the participant is taking the sentence literally, such that it is the ball that is doing the kicking. And after an example like (c), we might ask “Did Mary receive something / someone?”. What is literally said in this sentence is that Mary is given to a book, so if people understand this literally (without any inference from errors), then they should say no. If however they say yes, then this means that they probably inferred that the word “to” got left out.
The results of these experiments showed that people often infer the more plausible meaning in examples involving a single deletion from the more plausible alternation, as in example (c) above: that is, people often interpret “I gave a book Mary” as “I gave a book to Mary”. But people are much less likely to make such an inference when the inference involves an insertion as in (d) “I gave Mary to a book”, or when the inference involves making 2 insertions or deletions, as in (a) and (b). In these kinds of cases, people are near ceiling in usually interpreting the sentences literally.
The results of these experiments provide strong evidence for the noisy channel idea, since, across five alternations, the results were highly robust: (a) people almost never made inferences when there were two edits needed; and (2) people were much more likely to infer an error for a single deletion than a single insertion, for all 3 single-edit constructions.
It is still an open question as to what the correct noise model is. In the paper we assumed deletions and insertions, but it could be deletions and swaps (along with a distance constraint on swaps, such that shorter swaps would be more likely). But whatever the noise model, it needs to explain (a) the large asymmetry between deletions and insertions (which can be explained by the assumption of a deletion component to the noise model); and (b) the large effect of 2-edits vs. 1-edit, such that people are more likely to infer the plausible alternative for single-edit examples.
2. Noise in the environment.
The rational inference approach to language comprehension predicts that if there is a higher level of noise in the environment, then people will make more inferences toward plausible alternatives. We tested this idea by adding noise to the distractor items in the experiments, and examining people’s interpretations on the same examples as in the original experiments. The noise consisted of added, deleted, and swapped words in 20 of the distractor items (but the target items were identical to those in the other experiments). In the single-edit examples (such as the DO/PO construction), the presence of noisy distractor items caused participants to infer the plausible alternative, on about 10-15% more of the trials. The noisy fillers had no effect on the 2-edit versions (probably because the edits are still too unlikely).
3. People’s prior expectations on what people are likely to say.
The rational inference approach to language comprehension also predicts that the prior will affect the kinds of inferences that are made. In particular, if the speaker / writer produces more implausible sentences, then experimental participants should make fewer inferences of production errors, and hence they should interpret the implausible sentences literally more often. We manipulated the prior expectations by combining all five experiments into one larger experiment, so that there were 50 implausible sentences, together with 50+60 = 110 plausible sentences. The results of this experiment were as predicted: people interpreted the one-edit materials more literally than in the baseline original experiments, again by 10-15%. (There was no effect on the two-edit materials, because they were already interpreted literally close to 100% of the time.)
Language comprehension in persons with aphasia
It has long been known that persons with aphasia interpret implausible non-reversible sentences like “The ball kicked the girl” as their plausible alternative (“the girl kicked the ball”) more than non-language impaired control participants. We recently proposed that perhaps this
It has long been observed that, when confronted with an implausible sentence like The ball kicked the girl, individuals with aphasia rely more on plausibility information from world knowledge (such that a girl is likely to kick a ball, but not vice versa) than control non-impaired populations do (Caramazza & Zurif, 1976). We offer a novel hypothesis to explain this greater reliance on plausibility information for individuals with aphasia. The hypothesis is couched with the rational inference approach to language processing. A key idea in this approach is that to derive an interpretation for an input string, individuals combine their priors (about messages that are likely to be communicated) with their knowledge about how messages can get corrupted by noise (due to production or perception errors). We hypothesize that language comprehension in aphasia works in the same way, except with a greater amount of noise, which leads to stronger reliance on syntactic and semantic priors.
We evaluated this hypothesis in an act-out task in three groups of participants (8 individuals with aphasia, 7 older controls, 11 younger controls) on two sets of materials: (a) implausible double-object (DO) / prepositional-phrase object (PO) materials, where a single added or deleted word could lead to a plausible meaning; and (b) implausible active-passive materials, where at least two added or deleted words are needed to arrive at a plausible meaning.
We observed that, similar to controls, individuals with aphasia rely on plausibility to a greater extent in the DO/PO than in the active/passive alternation. Critically, however, as predicted, individuals with aphasia rely less on the literal syntax overall than either of the control groups, and use their world knowledge prior (plausibility) in both the active/passive and DO/PO alternations, whereas controls rely on plausibility only in the DO/PO alternation.
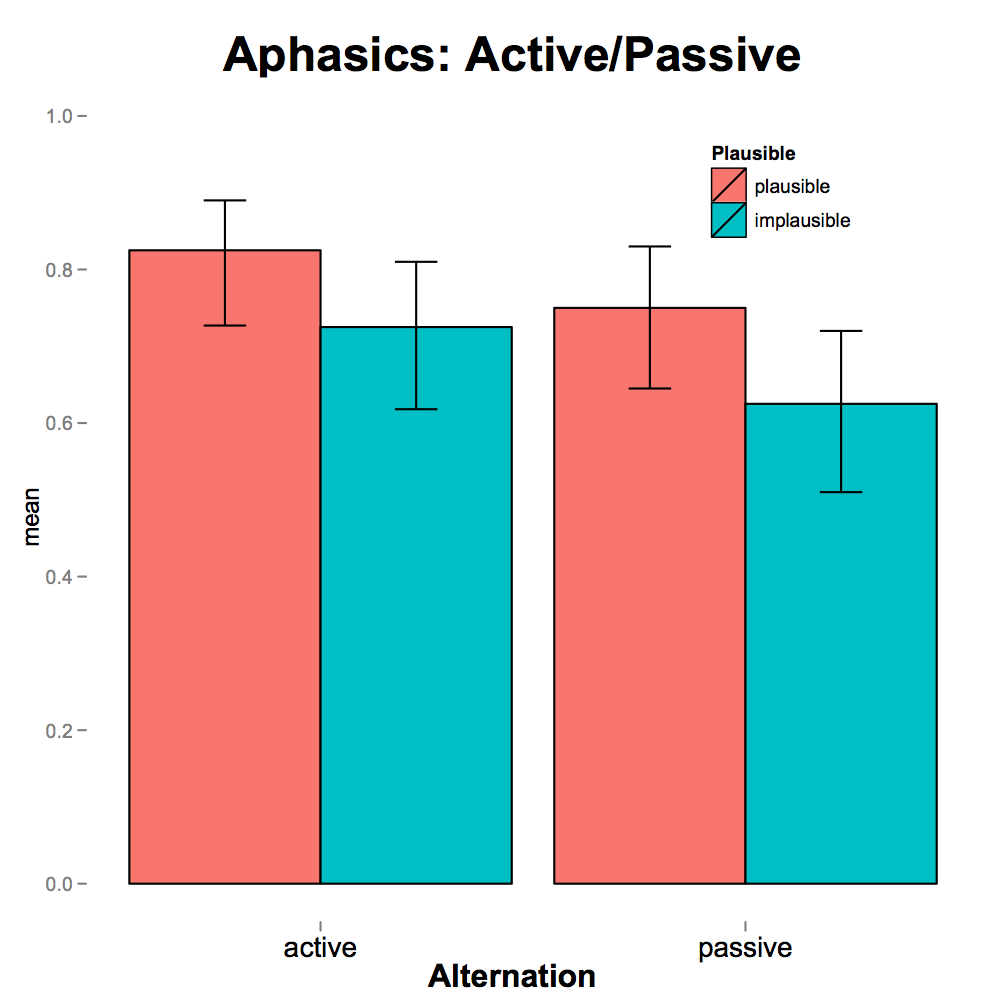
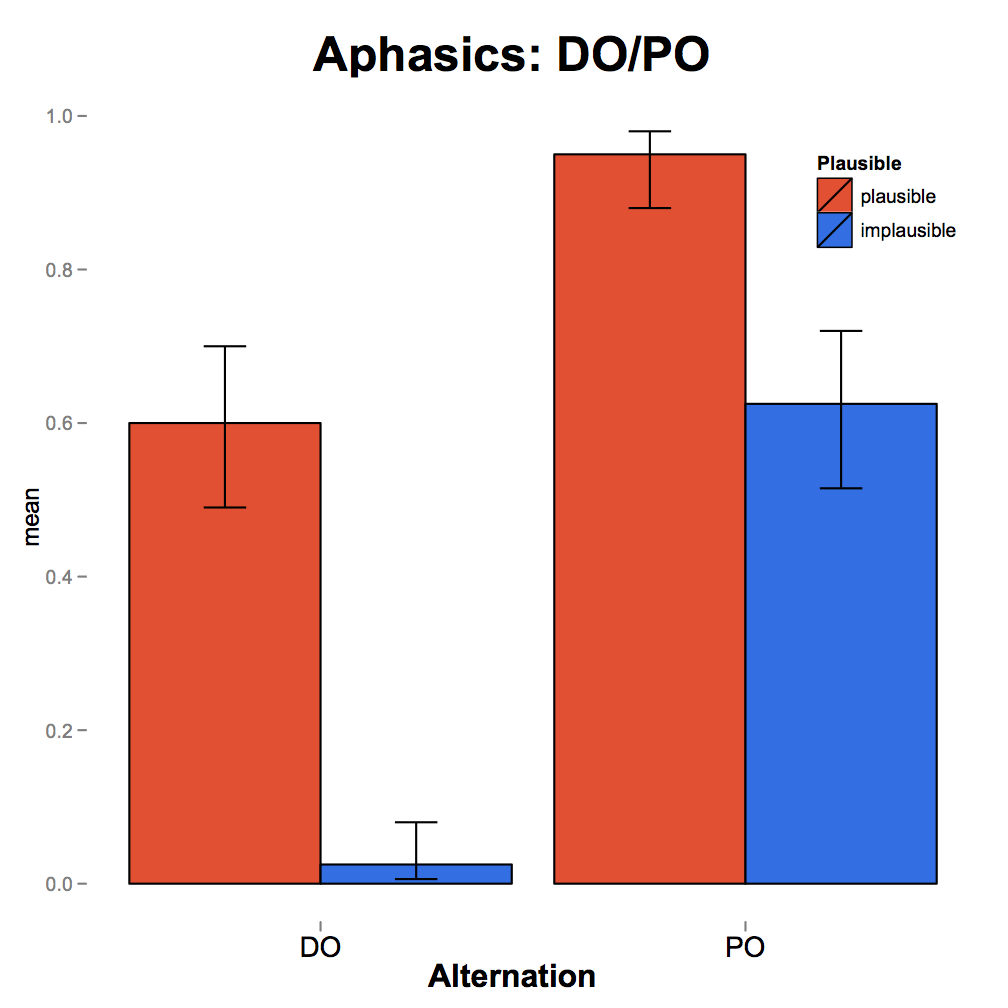
Persons with aphasia rely more on semantics in minor-edits (DO/PO) than in major-edits (active-passive), similar to other populations. But unlike control populations, persons with aphasia seem to rely on plausibility for interpretation of implausible active and passive sentences. In addition, older persons and persons with aphasia made more errors on the DO structures (which are less frequent than PO structures) independent of plausibility, thus providing evidence for reliance on a syntactic prior, the more frequent structure. Overall, these results are as predicted by the rational inference approach to language processing in individuals with aphasia.
Rational Inference and agreement errors
In this project, we apply the noisy-channel idea to investigate a phenomenon that has traditionally been interpreted in terms of failures of the sentence production system: subject-verb agreement errors. In a standard sentence elicitation paradigm, experimental participants are presented with an initial sentence preamble (e.g., The key to the cabinets…) and are asked to repeat the preamble and continue it to make a complete sentence. The basic finding is that agreement errors are most likely to occur when the head noun (key) is singular and the local noun (cabinets) is plural, where participants often mistakenly produce a plural verb, as in The key to the cabinets are…. Agreement errors rarely occur for the other three combinations of number marking, including, interestingly, the plural-singular combination (e.g., The keys to the cabinet is…) (Bock & Miller, 1991).
According to one class of accounts, these errors occur when number features are incorrectly propagated through a sentence’s syntactic tree (Vigliocco & Nicol, 1998; Hartsuiker, Antón-Méndez & van Zee, 2001; Franck, Vigliocco & Nicol, 2002; Eberhard, Cutting, & Bock, 2005). Critically, in order to account for the observed asymmetry between singular-plural and plural-singular error elicitations, these feature-passing accounts postulate an asymmetry in the “markedness” of different noun endings, such that singular nouns are unmarked, and plural nouns are marked. A second class of accounts views agreement errors as resulting from memory encoding or retrieval difficulties at the interface between the sentence production system and memory (Solomon & Pearlmutter, 2004; Badecker & Kuminiak, 2007; Wagers, Lau & Phillips, 2009; Dillon, Mishler, Sloggett, & Phillips, 2013). These accounts require the same markedness stipulation in order to account for the data.
In contrast, we propose that agreement errors in the sentence elicitation task result from rational properties of sentence comprehension in this task. In particular, given that participants must first understand the sentence preamble, the agreement error pattern can be straightforwardly explained by the comprehender’s attempt to infer the producer’s intended signal given the possibility of noise. In performing this inference, comprehenders rationally integrate their expectations about the intended meaning with their knowledge of the noise process, which can be described in general terms as follows:
(i) P(s_i | s_p) ∝ P(si) P(s_i → s_p)
In this equation, s_p is the linguistic signal that the comprehender perceives, and s_i is the signal that the producer intended. The comprehender’s goal is to find the intended meaning that maximizes P(s_i | s_p): the probability that the producer intended s_i given that the comprehender encountered s_p. By Bayes’ rule, this probability is proportional to a) the prior probability P(s_i) that si was intended by the producer, multiplied by b) the likelihood P(s_i → s_p) that noise would transform s_i and cause the comprehender to actually perceive s_p (the arrow represents the transformation of s_i to s_p). The prior probability P(s_i) takes into account the comprehender’s expectations about what the producer is likely to say – incorporating both linguistic and world knowledge – whereas the likelihood P(s_i → s_p) represents the kinds of noise the comprehender expects.
According to this approach, agreement errors result when comprehenders rationally, but incorrectly, infer the presence of noise, and consequently misinterpret the signal. In particular, agreement errors occur when the initial (head) noun is inferred to have an incorrect number marking. Comprehenders are predicted to be most likely to make incorrect inferences about a noun’s number marking in precisely the conditions where agreement errors are most frequently observed: when the head noun is singular and the local noun is plural. This prediction can be broken into two parts, as summarized in Table 1 and elaborated next:
| Head Noun | Local Noun | Errors predicted? | Reason |
|---|---|---|---|
| Plural | Plural | No | Insertions are unlikely |
| Plural | Singular | No | Insertions are unlikely |
| Singular | Plural | Yes | Deletions are likely; lower base rate |
| Singular | Singular | No | High base rate |
Table 1: Explanation of the noisy channel account’s prediction that agreement errors should be most likely in the singular-plural condition.
- Agreement errors will occur more often when the head noun is singular. In the noisy channel framework, this prediction can be recast as follows: comprehenders will mistakenly infer that a singular head noun is plural more often than the reverse. Following prior work on noisy channel comprehension theories (Levy 2008, Levy 2011, Gibson, Bergen, & Piantadosi 2013), we assume that there are two types of relevant noise: insertions and deletions. In English, the insertion of “-s” or “-es” transforms a singular noun into a plural noun, while the deletion of this suffix/string transforms a plural noun into a singular noun. Comprehenders will mistakenly infer that an observed singular noun is a plural noun if they infer that an ending was deleted from the plural noun, and they will infer that an observed plural noun is a singular noun if they infer an insertion onto the singular noun.
The noise likelihood P(s_i → s_p) should assign higher probability to deletions than insertions. This prediction holds for a range of plausible noise models, and follows from the Bayesian size principle (Xu & Tenenbaum, 2007; MacKay, 2003; Gibson, Bergen & Piantadosi, 2013): a deletion only requires a particular morpheme (or sequence of letters) to be selected from a sentence, whereas an insertion requires its selection from the producer’s (large) inventory of morphemes or letters. The deletion of a specific sequence therefore has higher likelihood P(s_i → s_p) than the insertion of that sequence, even assuming that insertions and deletions occur equally often. Thus, the transformation of a plural head noun to a singular head noun, which requires a deletion, is more likely than the reverse transformation, which requires an insertion.
- Agreement errors will occur more often when the head noun is singular and the local noun is plural than when both the head and local nouns are singular because of properties of the prior distribution P(si). An analysis of the Switchboard corpus of spoken American English (Godfrey, Holliman, & McDaniel, 1992) showed that singular-singular prepositional phrases are 3.5 times as frequent as singular-plural phrases, 5 times as frequent as plural-singular phrases, and 6 times as frequent as plural-plural phrases. As demonstrated in the Appendix, this frequency distribution makes it unlikely that another construction was intended if a singular-singular PP is presented, whereas it is more likely if a singular-plural PP is presented. Jointly, parts 1) and 2) establish that agreement errors should occur most frequently for singular-plural constructions
A clear advantage of the noisy channel framework over previous accounts is that the concentration of errors in singular-plural constructions is predicted on independent grounds, and does not need to be stipulated. Moreover, the inferential mechanisms required to explain this pattern are not special to this phenomenon, and have been argued for more broadly in earlier work.
We discuss many further predictions of the noisy-channel framework in sentence-completion paradigms, using agreement error
Rational Inference and the P600 in ERPs
One well-known ERP phenomenon is the P600, first discovered by Osterhout & Holcomb (1992) and Hagoort & Brown (1993). Originally, it was thought that the P600 waveform indexed syntactic surprisal, such as for (b) relative to (a):
a. Every Monday he mows the lawn.
b. (*) Every Monday he mow the lawn.
The verb “mow” does not agree with the third person singular noun “he”, and hence (b) is ungrammatical. People experience a P600 for (b) relative to (a): a positive going voltage wave, such that the difference wave with the control (a) peaks around 600 msec after the onset of the ungrammaticality (mow vs. mows).
However, we propose that the P600 is not due to ungrammaticality detection: we propose that this waveform indexes people’s ability to correct an ill-formed input into something that makes more sense (in this case, correcting “mow” to “mows”). We call this the rational error correction account of the P600. Thinking about the P600 in this way allows us to explain several otherwise surprising P600 phenomena in the literature. First, a P600 occurs for the “traditional” syntactic violations (e.g., number/gender/case agreement, etc.) and for other minor deviations from the target utterance (e.g., spelling errors, such as “fone” instead of “phone”; Munte et al., 1998), because a close alternative exists in these cases, which the comprehender can infer and correct to. Similarly, this account explains “semantic P600” cases, such as the P600 which occurs for (d) relative to (c) (Kim & Osterhout, 2006; Kuperberg et al. 2003):
c. The hearty meal was devoured…
d. The hearty meal was devouring…
In this case, a close alternative exists that the producer plausibly intended (e.g., devoured instead of devouring) so that correction can occur, and the P600 results. Furthermore, no P600 occurs for “traditional” semantic violations like (f) relative to (e) for which the standard N400 effect occurs, indicating implausibility in the context (Kutas & Hillyard, 1980), because no likely error correction is possible in those cases:
e. I take my coffee with cream and sugar.
f. I take my coffee with cream and dog.
That is, when someone says I take my coffee with cream and dog, the probability of a noise process that changed something more plausible in the context like sugar, sweetener, etc. to dog is very low. Thus no P600 is expected.
Our paper on this topic is currently under revision.
A noisy-channel account of cross-linguistic word order variation
Human languages vary not only in the different ways that words convey meaning, but also in the way that the words get put together. For example, if you want to say “the girl kissed the boy”, you use the same word order in English, French, Chinese, or Spanish: subject or agent first, then the verb, then the object or patient: so called “subject-verb-object” (SVO) word order. But if you want to say that idea in Japanese, Korean, Hindi or Turkish, then you use a verb-final word order, such as “girl boy kissed”. Let’s look at how word orders are distributed across many of the world’s languages, from the World Atlas of Linguistic Structures (WALS, Dryer & Haspelmath, 2013, http://wals.info/ ):
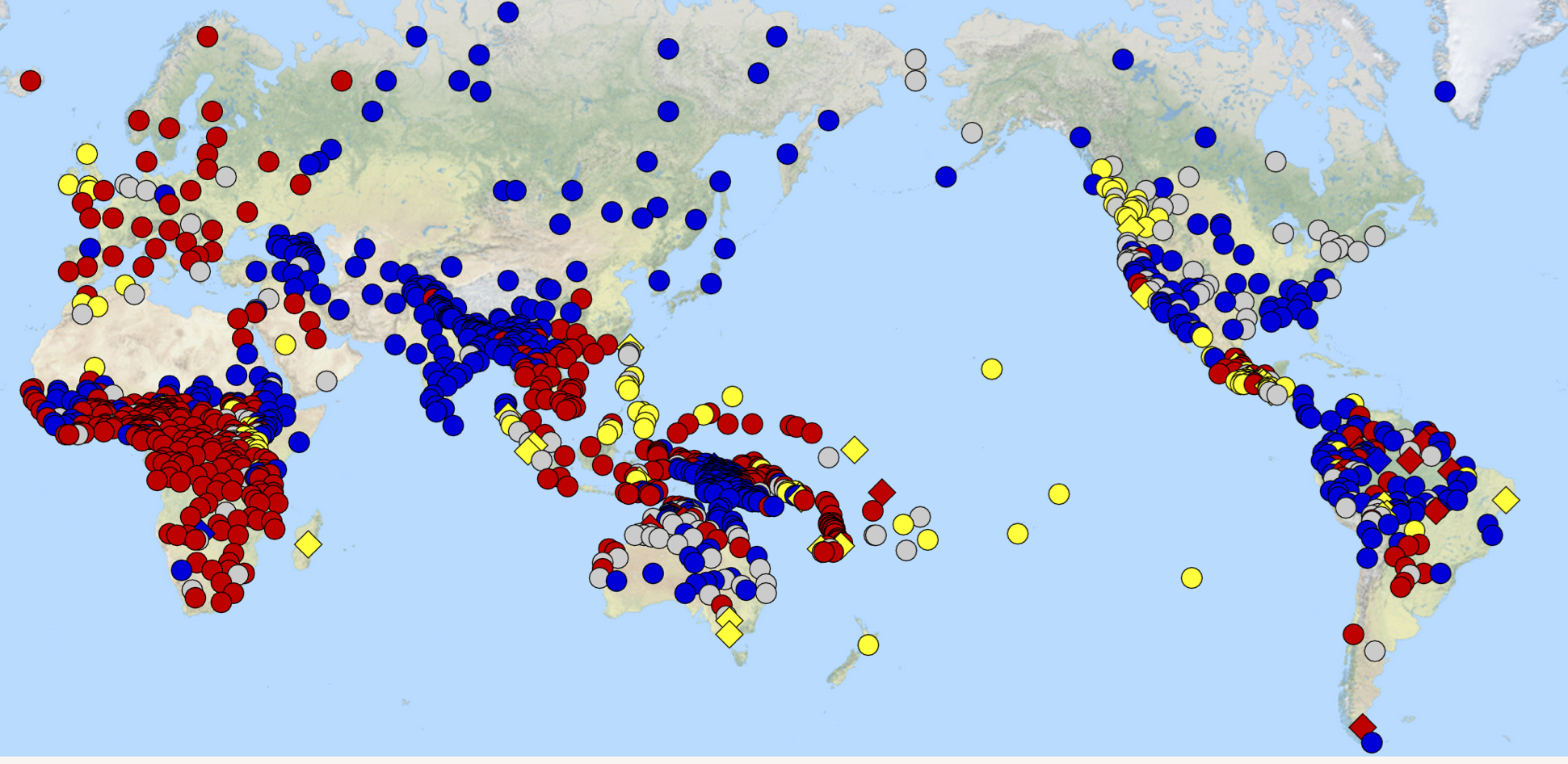

English is an SVO language under the WALS characterization because most sentences in English with an S, V and O are ordered SVO. But there are exceptions. For example, I can topicalize the object, to say “Accordions, Steve really likes a lot”, an OSV word order. So we should really have probabilities for each word order in each language, not just 0s and 1s. The WALS people decided that a word order is a “dominant” word order if over 2/3 of its sentences with S, V and O in them are that order. So German and Dutch (which have well understood word order) are listed as “no dominant order” in this picture, because they have lots of SOV and SVO word orders.
(Note that English is located only once on the map, in England. The SOV / no dominant word order / VSO languages in North America are native American languages.)
A couple of generalizations pop out when you look at a lot of languages across the world. First, there are lots of SOV and SVO languages, and some VSO languages, but there are very few VOS, OSV and OVS languages. This is an observation first due to Greenberg (1963): that most languages have a subject-before-object word order. MacWhinney (1975) suggested that maybe this is because people like to talk about human / animate things (including themselves), so they tend to start with the human thing (which tends to be the subject / agent) and continue to the other entities in the event (which are often inanimate things).
A second generalization is that most of the languages are either SOV (like Japanese) or SVO (like English and Chinese). Why might this be? We offer an information theoretic account of part of this.
Part 1 of the information theoretic account is that SOV (like Japanese) may be the most basic word order, the easiest for humans to use. Some evidence for this idea is that the word order for two independent recently formed sign languages which evolved with no precursors are both SOV: Nicaraguan Sign Language (Senghas, Coppola, Newport, & Supalla, 1997) and Al-Sayyid Bedouin Sign Language (Sandler, Meir, Padden, & Aronoff, 2005). Further evidence for this idea is that in gesture production tasks, where people are brought into a lab and asked to act out or gesture the meanings of simple events (like a girl kicking a ball), all participants gesture SOV for simple events, even people who speak SVO languages, like English, Spanish, Chinese (Goldin-Meadow, So, Ozyurek, & Mylander, 2008), Italian (Langus & Nespor, 2010) and Russian (Futrell, Hickey, Lee, Lim, Luchkina & Gibson, 2015) and even VSO languages like Modern Irish and Tagalog (Futrell et al. 2015).
See Gibson et al. (2013) for more.
Part 2 of the information theoretic account to word order is the most exciting idea. The idea here is that communication over a noisy channel favors a shift to SVO word order. In particular, suppose we want to convey “girl-agent boy-patient kiss” (the girl kissed the boy). One of the main ways that noise can corrupt a signal is through information loss: we miss a word or two. Now imagine that I lose one of the nouns when using an SOV code: I then also lose the information of how the remaining noun connects to the verb. So if I hear “girl kiss”, is the girl the subject? Or the object? We don’t know.
Now consider an SVO code. Now if I lose one of the nouns, I still know how the remaining noun connects to the verb. That is, if I lose the subject, I am left with “kiss boy” and I know that boy is the object. And if I lose the object and I am left with “girl kiss” then I still know that girl is the subject. So SVO word order is more robust to noise than SOV.
So the combination of these ideas can potentially explain why human language’s word orders look the way that they do. SOV word order is the most basic, so lots of the world’s languages are SOV. And then, when there is confusion about human patients of verbs, languages often shift to SVO word order, like English.
But if SVO word order is more efficient, then why aren’t all languages SVO? It turns out that there is a simple answer: there is another way that languages have evolved to communicate relationships between words: Case-marking. In a case-marking language, we add a word to the end of each noun to indicate its role in the sentences. So in Japanese, we say girl-subject boy-object kissed. By adding this extra word, we add redundancy to the code, so now if we happen to lose one of the other words (like the subject for example) we still have a word saying what the role of the object is. Notice that English doesn’t have case-marking: we say “boy” and “girl” in exactly the same way whether they are subject or object in a sentence: the boy kissed the girl; or the girl kissed the boy. Now, with the possibility of case-marking, a language with the simplest conceptual word order — SOV — doesn’t have to shift to SVO to be robust to noise. It can stay at SOV by keeping the extra words to get the roles across, so called “parity-bits” in information theoretic terms. To test this idea, we look at the relationship between case-marking and word order, and it turns out that there is a striking relationship. Almost all SOV languages (like Japanese, Turkish, Hindi) are case-marked. And most SVO languages (like English, French and Chinese) are not (data from Dryer, 2002):
| SVO | SOV | |
|---|---|---|
| % Languages | 72% | 14 % |
| 181/253 | 26/190 |
Table 2. Percentages of languages with case marking for subject and object by word order type.
And there are many other ramifications of the information theoretic approach to word order.
Case-marking can be dependent on whether the object is human or not: So some languages just case-mark the most confusable nouns: the human objects. E.g. Persian. These are called Differential Object Marking languages.
Consider Creole languages: languages created when several languages come into contact, and there are speakers who know none of them: they speak a degenerate language, a so-called pidgin. But their children generalize the pidgin into a full blown language, a so-called Creole, such as Haitian Creole. Because it turns out that morphological endings like case-markers are hard for second language learners to learn (Lupyan & Dale, 2010), Creoles usually end up being SVO, even when some of the contact languages are SOV. Without case-marking, the word order goes to SVO.
Consider the example of Old English to modern English. Old English was a case-marked SOV language. After a lot of language contact, presumably the case-markers were hard to learn for the new learners of English, and it shifted to SVO, and lost the case-marking.
Dependency length minimization across languages
Richard Futrell led this project in which we sought to gather parsed corpora from as many languages as we could. Given the parsed corpora, we could evaluate hypotheses about why languages might look the way that they do. The World Atlas of Linguistic Structures (WALS, Dryer & Haspelmath, 2013, http://wals.info/) has information about many languages, but it doesn’t contain parsed corpora, so it is difficult to evaluate probabilistic hypotheses using WALS.
Once Richard had gathered enough parsed corpora, one of the first things he did was evaluate whether dependency distances are minimized in most / many languages, as had been hypothesized in the literature. Dependency lengths are the distances between linguistic heads and dependents. In natural language syntax, roughly speaking, heads are words which license the presence of other words (dependents) modifying them. For example, the verb threw in Sentences A & B in Figure 1 licenses the presence of two nouns, John - its subject - and trash - its object. Subject and object relations are kinds of dependency relations where the head is a verb and the dependent is a noun. Another way to think about dependency is to note that heads and dependents are words which must be linked together in order to understand a sentence. For example, in order to correctly understand Sentences A & B below, a comprehender must determine that a relationship of adjectival modification exists between the words old and trash, and not between, say, the words old and kitchen. In typical dependency analyses, objects of prepositions (the him in for him) depend on their prepositions, articles depend on the nouns they modify, and so on. The figures below show the dependencies involved in some example sentences according to the analysis we adopt.
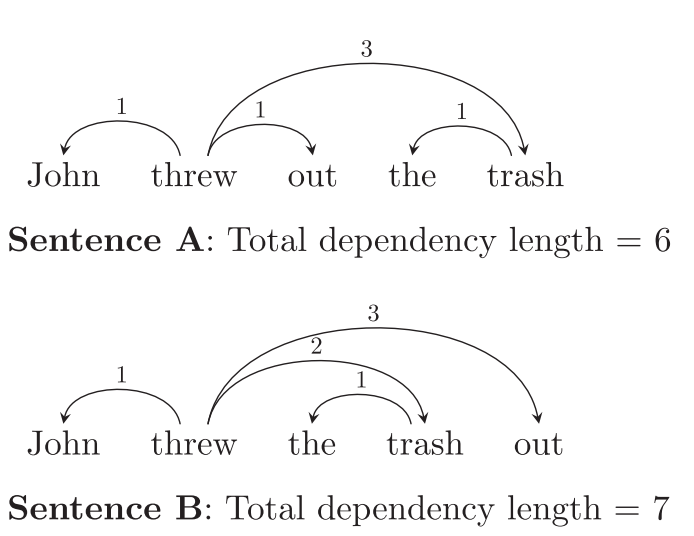
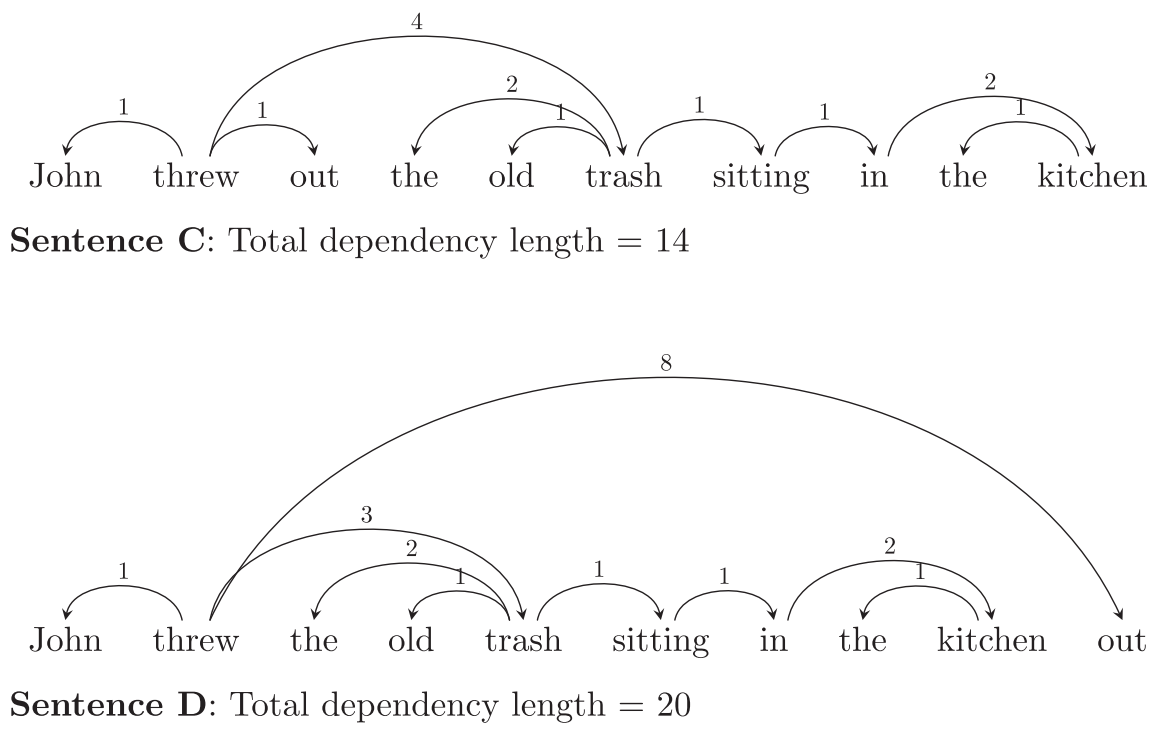
The DLM hypothesis is that language users prefer word orders which minimize dependency length. One early incarnation of DLM hypotheses is the Dependency Locality Theory (DLT, Gibson, 1998, 2000). According to the DLT, longer distance dependencies are harder to comprehend and produce than more local ones (cf. other memory-based hypotheses: Yngve, 1960; Chomsky & Miller, 1963; Bever, 1970; Hawkins, 1994; Lewis & Vashishth, 2005). So the dependency between “wrote” and “reporter” is proposed to be more difficult to comprehend in c than in b than in a, as more words / discourse referents are added between the two words:
a. The reporter wrote an article.
b. The reporter from the newspaper wrote an article.
c. The reporter who was from the newspaper wrote an article.
A canonical kind of sentences that are hard to process because of long-distance dependencies is nested or center-embedded structures. Here are some English and Japanese examples of nested structures:
English:
d. The reporter [ who the senator attacked ] admitted the error.
e. The reporter [ who the senator [ who I met ] attacked ] admitted the error.
f. Non-nested control, meaning approximated the same thing as (e):
I met the senator who attacked the reporter who admitted the error.
In the English example e, there are long-distance dependencies between “reporter” and “admitted”, and between the first “who” and the verb “attacked”. In the control f, all dependencies are local.
Japanese:
g. Obasan-wa [ bebiisitaa-ga [ ani-ga imooto-o ijimeta ] to itta ] to omotteiru
aunt-top babysitter-nom older-brother-nom younger-sister-acc bullied that said that thinks
“My aunt thinks that the babysitter said that my older brother bullied my younger sister”
h. Less nested control:
Bebiisitaa-ga [ ani-ga imooto-o ijimeta ] to itta ] obasan-ga to omotteiru
In the Japanese example g, there is a long-distance dependency between the subject (topic) “obasan-wa” (aunt-topic) and the verb “omotteiru”. In the control h, the subject “obasan-ga” (aunt-subject) is immediately adjacent to the verb “omotteiru”.
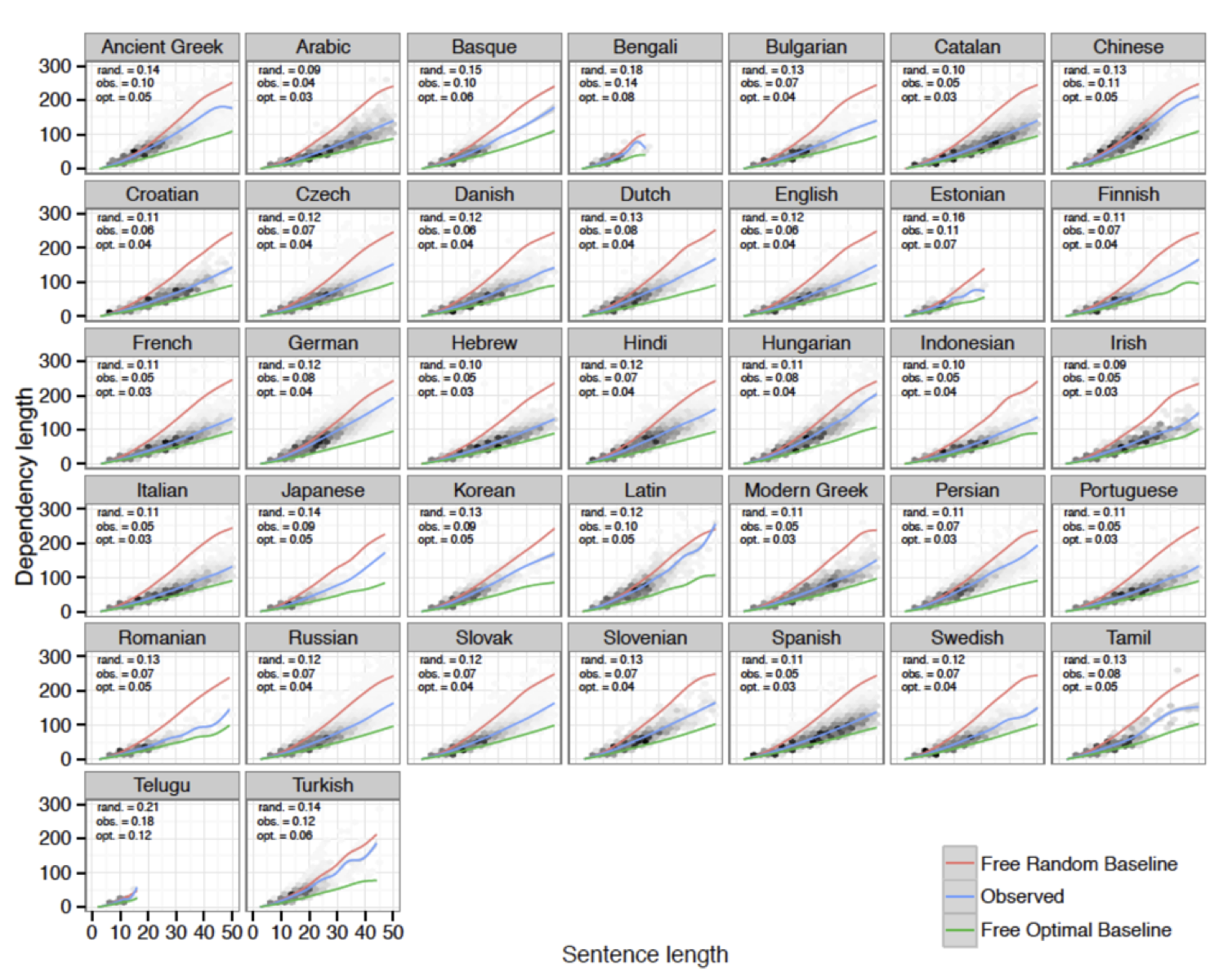
In order to investigate whether sentences in a corpus tend to minimize dependencies, we compared the parses of sentences in the existing corpora to other potential ways of saying the same things, within a language. We operationalized this idea by taking each sentence in a language’s corpus, and finding all the dependents of the root node, and then scrambling the head and dependents in a random order. E.g., suppose the root is the verb “gave” in the sentence “John gave a book to Mary”. Then we would take the head “gave” and the three dependents “John”, “a book” and “to Mary” and scramble them. Then for each dependent, we would repeat this process all the way down the tree. We would do this 100 times for each tree in each corpus. Then we compared the dependency lengths for these baseline-generated dependency trees to the ones that actually occurred. We see that the dependency lengths in real sentences are shorter than those in the existing corpora. This is statistically significant in all 37 languages we examined, after sentence lengths of 12 or more (below that, the dependencies are often not long enough to make a statistical difference). We also compared real dependency trees to an even more conservative baseline: one in which all the trees are constrained to be projective (which means that we disallow any crossed dependencies). This is an even more conservative baseline because many of the long dependencies in the non-conservative baseline cross other dependencies and are therefore non-projective. Even using this conservative baseline, all 37 languages have shorter dependencies in the real corpora compared to the baseline. See the figure below for a comparison among dependency lengths for the real parses vs. the conservative random baseline, and an optimally short baseline, for each language. As you can see, all languages fall between the random baseline and the optimal baseline.
An interesting question is whether it is the grammar of the language that is partially optimized for dependency length minimization, or whether the grammar may allow multiple word orders for some dependents, and the dependency length minimization is a property of the processor. This turns out to be a hard question to answer using our corpora, because they aren’t big enough to know what makes a rule part of the grammar or not. But we can imagine that both factors may be playing a role. In particular, the examples in sentences C and D above (“John threw out the old trash sitting in the kitchen”, “John threw the old trash sitting in the kitchen out”) are both grammatical ways to say the same thing: one happens to have shorter dependencies, and is easier to process. But languages may also be partially optimized for dependency lengths. For example, we know of no examples of languages that are head-initial with respect to verbs and their complements, and head-final with respect to complementizers (like the word “that” in English, which marks an embedded sentence), or head-final with respect to verbs and their complements and head-initial with respect to complementizers. If a language had opposite values for the head direction verbs and complementizers, then it would have very long dependencies:
